I'm working on a system for positive behavioral recognition and metrics using Firebase and React. This is a hobby/side project that I work on usually on nights and weekends.
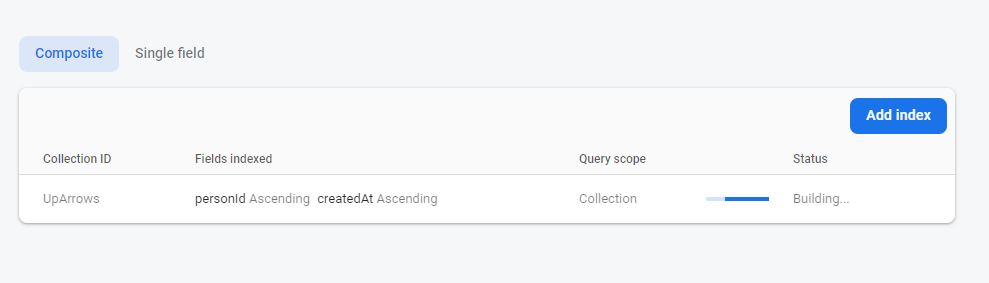
This weekend I had an issue with Firestore (the newer of the two data solutions inside the Firebase product). I was querying on multiple data attributes in a collection. This is not allowed in Firestore, unless you have created an index that includes those two attributes.
I had no such index, so I got this error:
Does that say, "You can create it here:" ?
Yes, the short answer is that that link says, "You can create it here." And you can click on it and it takes you to the page where you can build the index.
AND...
And it has pre-populated the index for you with the two fields that you need so that you can click, "OK". And the index builds, just like you need it:
OK, thanks, that was easy.
This is really pretty amazing and I have never seen an error like this.
Often, errors are very generic and it takes time to search through forums trying to find someone with the same error who is actually having the same problem as you.
I have seen a number of errors in React that offer suggestions as to where your bug is and they are often correct. This is very helpful and a huge improvement.
The Firestore error takes that level of customer service to a new level: here's your problem, here's how to fix it, and here's a link that will basically fix it for you.
I would very much like to see more of this.
What has happened here is that someone at Google (Firebase is a Google product) has applied the ideas of user experience to the error handling in their product. Developers are the users of the error system, so thank you for that!
Firebase is a web-based product, so there is no reason why it can't know enough to point you in the right direction.
If you are in software development, though, you can appreciate that this is a high bar to jump over:
Someone had to think of this early on, so that it could be woven into the product.
Leadership had to include time and budget to implement it.
Their UX had to be consistent enough to allow it.
The error system handling system had to be built smart enough to make it all work.
All of this to say - a lot had to happen technically, organizationally, and culturally to make this happen.
When you think about the amount of time that often goes into error handling and management, it makes this all the more amazing.
Developers ARE the users of your error system, your API, your toolkits, and your documentation. Doing things like this makes your tool attractive to developers, managers, and business decision makers.
Why managers and business decision makers? Because it makes good developers better and faster, and it makes new developers far more productive than they would be if you didn't have it.
New developers spend a lot of time searching for answers online and asking more senior team members for help. Imagine a world where the platform itself can answer your questions and guide you through solving the problem.
Kudos to Firebase/Google on an amazing innovation.
It's always been a little strange to use this question in a business context. It is a polite greeting, a way of saying 'hi', but really 'hi and a little more'.
It isn't a brutally honest solicitation of a persons true feelings - most of the time.
Today, you could answer, "I'm feeling anxious." or "I'm nervous about the economy." and those would be honest answers. But they may not be what you want to project in that meeting.
And, it is now difficult to use 'fine' or 'good' the way we all used to, because you risk sounding dishonest or callous.
"What? You're fine? How can you be fine?"
Last week I decided that the best way to answer this question was to choose to answer positively, with a focus on gratitude.
So, when I attend a business meeting or sales call and someone says "How are you?" or "How are you doing?" my answer is that I'm grateful for something.
Grateful for my health.
Grateful my kids are learning at home.
Grateful that I have a job.
Grateful to be alive.
Grateful that it is spring out and the sun is shining.
All of these are true and are much more meaningful and uplifting to me than 'fine' anyway.
I may just keep doing it when Covid is less present in our lives.
Hopefully a lot less present and that will be one more thing to be grateful for.
For those unfamiliar with the acronym, VUCA stands for Volatility, Uncertainty, Complexity, and Ambiguity.
It is a relatively trendy way to describe our modern world. It is a VUCA place.
Of course, the world has always been three of those things - volatile, uncertain, and ambiguous, and maybe all four depending on who you ask. If you asked a farmer at any time over recorded history he could tell you that his fortunes and those of his family were impacted by things out of his control. The world of most people has always been, at least, V, U, and A.
It is only recently, where we came to think of the world as NOT those three things. i.e. We could expect a certain amount of regularity, certainty, and definitiveness. But alas (or maybe not), no more.
As the pace of knowledge creation, globalization, and business speeds up we are more exposed to VUCA and we must develop ways to prepare for and manage the world.
It helps if we realize that this is a state of affairs that we evolved to deal with - the acronym may be new, but the conditions really aren't. We humans evolved to meet these types of challenges, are brains are big and we can handle the related stress, assuming we put some time and energy into it.
As for complexity, I think humans have introduced a lot more of that recently, but I also believe we have the tools to manage that.
If you're looking for somewhere to start - use the 7 Habits of Highly Effective People you can cut down by a lot of VUCA simply by focusing on what is in your power to control. Eventually you will get more power, simply by not trying to change that which you can't. Steven Covey covers that much better than I can. If you haven't read it, read it. If you read it and forgot, read it again.
There are other books that deal with this subject head on, such as Dr. Alan Watkins' 4D Leadership. In that book Dr. Watkins outlines paths to personal development that make us more resilient and more capable to deal with all the V, U, C, and A that we run into.
Beyond that though, what other tools are available to help us cope with the VUCA-ness of our present world?
I'm a firm believer that art - engaging with it, thinking about it, looking at it, trying to understand it - makes us more tolerant of the VUCA world.
Here is how art helps with each of the 4 areas:
Volatility - Engaging with art a little bit every day can take you out of your comfort zone on multiple fronts and help to prepare you mentally for all those volatile challenges that you are going to face. Art itself can be volatile - as it relates to traditions or other art. And it can show us ways of grappling with volatility, such as French painters in the 19th century beginning to look at the urban landscape and explore outside the 'approved' arenas for artwork. Much of modern art is challenging and a great many people simply ignore or disregard it because it may be non-representational. Do they take the time to think about it? Do they consider why the artist wanted to challenge us as viewers?
Uncertainty - art is a means of digesting and facing the challenges of the world and allowing you to see how others wrestle with things. Don't want to think about war or crime or poverty or disease? Here it comes anyway. art exposes you quite directly to another mind. That mind may be wrestling with or interested in the same things as you, but doing so in very different ways. Reading a poem written by another person or looking at a painting can help to expose you to different angles and you will not always know what is coming. Also, because the artist is not providing you with a written set of instructions, you walk into every artistic experience with a certain degree of uncertainty that is instructive if you are willing to open up to it.
Complex - Art can deal with complex topics and it can be, in and of itself, quite complex. Re-reading or extended observation is often key. To really appreciate, sometimes, frankly, to understand, you need to spend some time to appreciate the art, maybe do some additional research on the subject matter. This is helpful to get us ready to ask questions and understand the complex systems and situations we confront. Move beyond your first impressions, move beyond your initial read. Re-evaluate, think, engage.
Ambiguous - Some art may attempt to get a hold of a subject and tie it down for explanation, but most art rarely does this. We are given the artist's point of view, but that point of view can be ambiguous. Even when it isn't ambiguous, our own reaction may be. Self-reflection and self-evaluation help us to grapple with such ambiguity. Do I agree with this? Would I have written it this way? Does this help?
This is not how art or art appreciation is taught, but it is how I have used it and I have found it useful.
At times, with the best work that you encounter, you can find an antidote to all this VUCA-ness. A well written book or poem that speaks to you deeply can make the world seem suddenly clear and not ambigous at all. Great art can lift you up and offer you new ways of seeing things. You won't find this all the time or in every interaction, but when you do it is a powerful and uplifting.
Even when you don't encounter this feeling, you can still improve your faculties and increase your mental resilience by engaging with and thinking about a difficult topic.
A few resources worth considering:
Look around - nearly everywhere you go has some artwork on display: photogrpahs, paintings, sculpture. Take some time to look at this stuff and think about it. Take a notebook with you, write things down.
Review You High School/College Syllabus - was there a book that you hated? Why did you hate it? Read it again as an adult and see if there is wisdom there that you overlooked.
Poetry Dail - I'm partial to Poetry Daily. They publish and re-publish the best of contemporary poetry. With a new, very good poem every day. It is worth the time, and it is always there, offering something new and challenging.
Not every piece of art will speak to you. Not every book will help. But every artwork can be turned around in the mind and examined for the resources it provides. If you find none, your mind has spent time engaged in an activity that strengthens it and which can provide you meaning in itself.
You're my manager and a leader in my organization. Could you please:
Understand my Work
Recognize great work when it is done by myself and others
Listen more, ask more questions, talk less
Be willing to have hard conversations (with me and with other leaders), when necessary
Be a defender of positive energy, in all situations
Bring energy and enthusiasm to spare so that you can lift up the whole team, when things are difficult
Help to find solutions in difficult situations
Predict the Future
Create a balanced space where I can be a whole person, but be protected from too many messy impacts from other people
Allow me to innovate and create room for innovation within our organization
Help non-specialists understand my special work and what makes me special
Offer feedback at the right moment - hitting me with constructive criticism when I am walking out of successful meeting takes away from the success of the meeting, find a better time even if you have to wait
Encourage me to stretch
Pick me back up again, when I have failed, encourage me to try again.
I work in technology, so maybe some of this stuff is specific to the tech world, but I don't really think so.
I have been asked for number 8 on multiple occasions, and I've also been asked to help people get better at predicting the future. We came up with a system for it, but of course it was imperfect.
Number 9 may be the hardest one to do. This is more difficult than predicting the future (if you work in a rational organization people will understand that you're doing your best to predict the future and that it is hard).
Even rational organizations may struggle with understanding why we need to let people have rooms to be their whole selves at work.
We need whole people to show up at work because we need their energy and innovation and you get this most effectively when people feel comfortable being who they are. You also have to have some order and some sanitizing and professionalism. This can be a tricky balance. Sometimes people's whole person is messy.
There were several things I deleted off this list that fall under the category of hard conversations.
Setting realistic goals is one of those things. We are often put under pressure to pursue unrealistic goals, a manager needs to push back on the unrealistic and make sure other leaders understand the trade-offs.
Another thing I removed was focus on the long term. Long-term sacrifices in favor of short-term gains are something we should consider carefully. A good manager will daylight the long-term costs and push for what will make his teams lives better in the long run.
Five and Six are different. Defending positive energy may not be a completely positive act. Once the act of defending the positive energy is done, you need to then supply positive uplift to bring everyone back up. The defense and uplift require two different approaches.
Vision is not on the list because this is a list about management.
Almost all leaders are managers, and all managers are leaders in some fashion.
But not all managers are visionary leaders. That skill can be learned, but it isn't required to be a great leader of people.
Is this hard to do? It is very hard to do everything well on this list, but then many things worth doing well are hard.
Providing everything on this list as a team is OK - it may be too much for any one person to do all of it. If you work with a great leadership team it may be that
Even still, you will probably feel a bit like the leader in the picture, at times. That is, isolated. Seeking other managers and leaders with whom you can share your insights and challenges is critical.
You will probably stumble. You will make mistakes. Being resilient isn't on the list, because we all need that in the VUCA world, not just managers.
Managers have to be resilient for others, as well as themselves, that is why we have 14.
In my last post I jumped right into the fray of describing a whole system for data-driven software development that includes normal stuff (Business KPIs, OKRs, Software metrics) but also some weird stuff - what I call Positive Behavioral Metrics. I didn't describe what I meant, so I am going to do that now.
I also didn't describe what to do with the other half of that coin - negative feelings and behavior - but I am going to do that separately, in a future post.
Positive Behavioral Metrics is keeping track and counting all the good stuff that people do. A system to do this (could be software-based or not) should have the following characteristics:
A means to create and track 'wins' or instances of people doing good stuff. This could be someone who gave a great presentation, won significant new business, or contributed to the positive roll-out of a new initiative. Really anything that is good (for individuals, teams, or the organization in general) - large or small does not matter. Concrete behavioral information is preferred - a specific good thing is better than a vague good thing. But honestly, even starting with vague is better than nothing.
Notification - the person should always be notified when someone recognizes them.
Notification of Others - the person's boss and their boss's boss (if applicable) should be notified about the good thing that was done.
Reports - a person should be able to go in and see all the good things that they did in a time period (last month, this year, a certain year) so that it can be used in reviews.
Track positive behavior to company values: any time that someone does something good and it is tracked, they person entering should have the ability to track this to some part of the company's values.
Provide a report on people who consistently recognize other people. These are your energy fountains - the people producing energy in your organization. This is another key number, in addition to the people who get recognized the most.
Organization-level Reports: should include reports on doers - those doing the good stuff and recognizers those doing the recognizing. For both you want to know how much of it is happening, where it is happening, and to be able to drill down and see who is doing it and who they work for.
This is really pretty straightforward - honestly this can be built for very little $$ and you could get away with 1,2, and 3 to get started. You don't need more than that.
Outside of the system, you need a program around the raw numbers and reports to really drive maximum effect. And I don't mean prizes or gift cards. I honestly think that tying it to rewards or awards isn't terribly interesting or effective.
I'm really talking about how this applies to people's growth, to their careers, and to their happiness. This is what will make it the most powerful. This should generally include:
Personal recognition - by which I mean, if you're in charge and you get the emails about people doing awesome stuff, then walk around or visit the people and talk to them and show them that you are aware of what they do. You can take them to lunch if you want, or have a dinner or something, but do some form of recognition where their peers see you talking to them about what they did.
Thank you notes - I'm personally terrible at this, but many people swear by it. Sending handwritten thank you notes to people (or their spouses) is something that can be very effective.
Use of reports - encourage people to review their data, especially at review time to be sure that they use this data when filling in their reviews or 360 evaluations.
Encourage managers to recognize - use the recognizer score to ensure that recognition is happening and that you have even consistent coverage in your organization.
There are many other things you can do. These are simple examplesthat you can start with that don't cost much but do build a lot of energy in your organization.
I've spent quite a while in companies where metrics and KPIs are important: they are valuable tools, when used correctly. Everyone is more empowered when they see the business succeeding and see their own role in making it happen.
But I chose the image for the header of this post intentionally - it shows people working together, not a bunch of numbers or a pie chart. This is because people must engage with the data, and ideally, they should be the ones requesting more data to do their jobs better. This only happens if you take them into account at the beginning of any such program and figure out what makes them want to succeed, and what they need to do their jobs better.
When it comes to KPIs and metrics, I've seen problems crop up with them that usually fall into 3 big categories:
The creation and roll-out is ham-handed and focuses on management without listening to people, understanding what they need or want, and addressing their fears. People will be afraid - engage the fear or risk the disengagement that will follow.
What happens if a business, department, or team has an off year/quarter/month? How can you keep team members engaged? How do you keep your KPIs or data-based management from feeling like a flogging?
How do you balance the contributions of teams and individuals? How do you strike a balance between team metrics that measure (and reward) team success vs. those that recognize individual contributions? Both are important.
Because I've been getting exposure to OKRs through some client work recently, I think it is worth looking into how a successful metrics/OKR system can be constructed and avoid the problems up above.
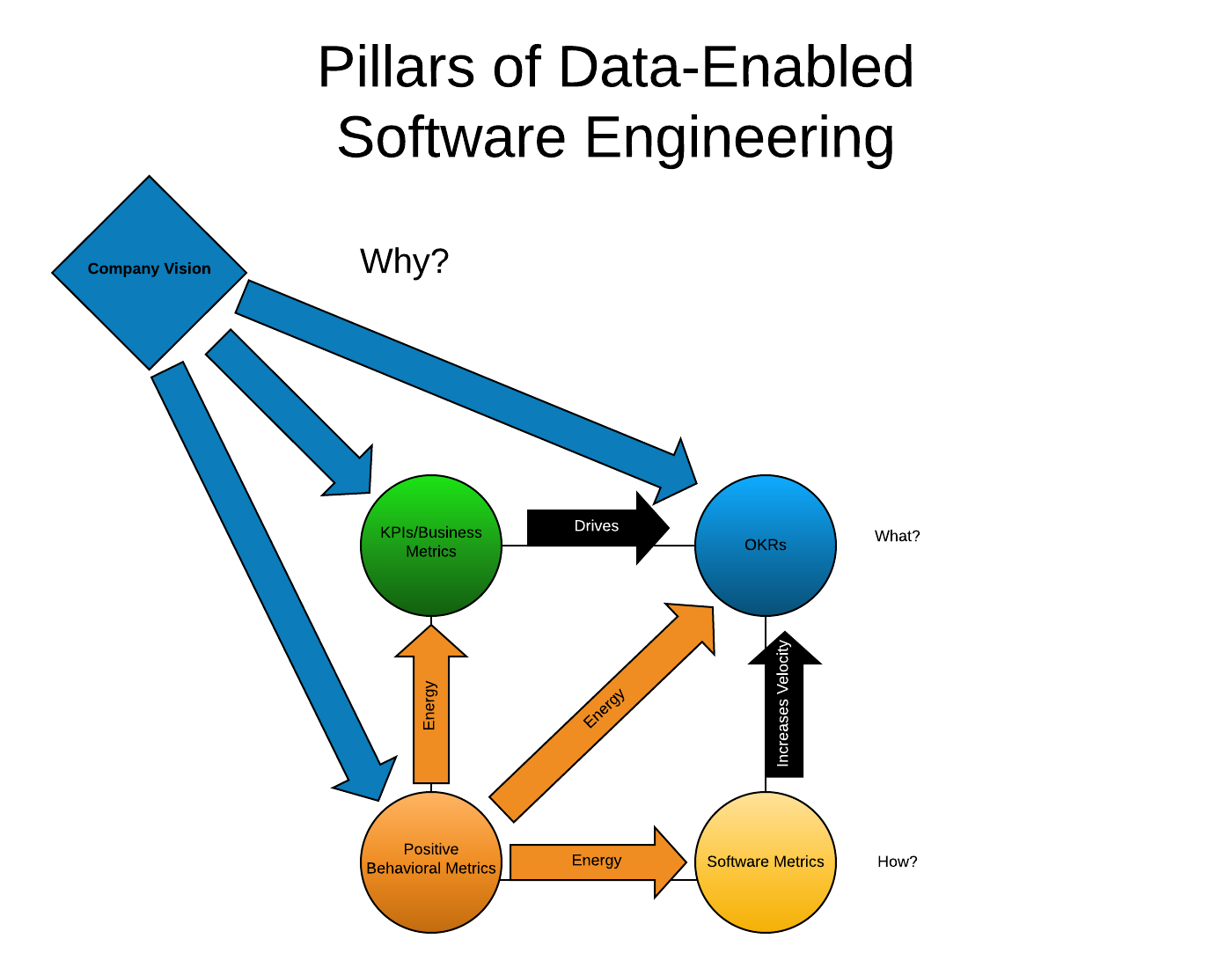
I have created this diagram to show how the elements should work together:
Here is a quick overview of the 5 major components:
Company Vision is critical. It really comes from outside and is separate from the pillars, but it influences them strongly and should determine (especially in the case of KPIs and OKRs) what they are. Company vision is the 'Why' of the company and you should see this strongly reflected in KPIs and OKRs.
KPIs (Key Performance Indicators) measure the ongoing business performance of the organization, including its profitability and how it achieves its vision. If your KPIs miss one of these marks (I've seen it) then your employees will be disconnected from it.
OKRs (Objectives and Key Results) - these are measurable goals that are more transitory than KPIs. OKRs should be a measure of what you are doing NOW (this month, this quarter, this year) in order to achieve and improve results. OKRs done well should result in improved KPIs - at their best they show us that we have selected the right work and done it well.
Software Metrics - this has proved elusive in organizations that I have worked for. What is the measure of good software development? What is the measure of a great developer? We're currently starting to use GitPrime - now part of Pluralsight, internally and with some clients. Good engineering metrics should result in agreed upon set of standards for software engineers, a high bar for quality of work, and they should drive us to deliver more and better features, so that we can do more valuable work.
Positive Behavioral Metrics - I will spend some time outside the bulleted list on why this is important and how this works. But if you're skimming this then you only need to know that the orange arrows tell you why this is important. When you have a down quarter, when a team struggles, what gives people energy and lifts them up so they can deliver anyway? What makes them carry on? What makes them feel that it is worth it to do so? This is driven by positive behavioral metrics.
Don't buy it? Wishing for comprehensive behavioral metrics? Let me explain why positive is so key here:
You never have to look far to hear negative behavioral information. It's there everyone knows about it, the focus here is to gather up the positive stuff to act as a counter balance.
Your other pillars - KPIs, OKRs, Software Metrics leave plenty of room for the realistic and pessimistic. If there are issues, they will show up there.
If you have a real, true behavioral problem on your team somewhere, you know it. You need to deal with it. Waiting around for a mid-year or annual review is wrong. The lack of presence of some type of negative ledger should create MORE urgency for you as a manager - not less. Deal with your drains, negatrons, and nasty actors - do it now.
HR already has systems and paperwork for negative behavioral problems. You don't really need another one.
An empty ledger says a lot - if someone has no items in their positive behavioral tracking system. Essentially the system for sending out positive vibes, you can assume that they are not a force for inspiration and energy on a team.
Link positive behavior to your company vision and guiding principles whenever possible. The arrows in the diagram show everything flowing out from your company vision, and this is how it should be. Your vision and mission (or whatever you call it) should be your barometer and benchmark for what you do. But, when people succeed, if you link this back to parts of your mission or principles, this can help to reinforce why what they did was important, and later on you can look at where and how your principles are being re-inforced, and see if there are any gaps worth thinking about.
Challenges with 'Comprehensive' Behavioral Metrics
In one of the organizations that was very metrics focused, we had a metrics section for behavioral traits. This was not exclusively about positive behaviors.
The rating's were from 1 (not at all cool in any way) to 5 (godlike).
There were a lot of 3's and 4's handed out by managers. Which was correct and how the scale was designed, but it lead, almost exclusively to problems.
Problem 1: Most people view themselves as 4s or 5s. As a result, the reactions that people had to pretty realistic, generally positive reviews (say a 3.5) was one of disappointment, "You mean I'm not a 5?" When the system was set up so that almost no one could ever get a 5.
Did anyone ever move up from being a 3 to a 5? A few, but it didn't have anything to do with the review process or the behavioral traits metrics. It had to do with great managers and mentors making a real difference in people's careers, so that they were uplifted and excited to come to work. Getting a 3 (out of 5) on a performance review never does that.
Problem 2: By the time you were handing out a 2 or a 1, it was too late and you should have fired that person already. I can think of only one exception to that, and it was a 2.5, not a 1.
This is why I have a pretty dim view of behavioral metrics, and see that focusing on the positive is the most valuable way to come at this.
The diagram up above is how I see this all working together. I am currently working with Weekdone for OKRs and I like how you can essentially set and use this at the granularity you prefer. You can have team OKRs and you can have individual OKRs, and they can roll up or not.
I think this is an excellent pivot point between the team/individual and it allows you to customize this to your needs.
For software development I think a lot of your engineering metrics are going to be on an individual level (# of commits, accepting pull requests, etc).
This allows you to keep KPIs at the global or divisional level, where I think it is good to have a strong focus on the team and the sum of the parts working together.
How To Get It All Done
"Sure," you say, "that is a nice diagram Jonathan, but who has time for all of this stuff?"
Or perhaps you say something less flattering.
This is a fair criticism, our time and our energy are our most precious commodities as leaders, so a bunch of extra paper pushing does not help anyone.
Here is a cost effective way to approach these, get started, and grow it as you see which is most valuable for you.
KPIs - Most KPIs should be an accounting function, and those that are not either should be, or they should be baked into the software product you develop as a key management function, end of story. Beware of special cases and subdivisions that make reporting on KPIs more work. Everyone should get the same measurement, that is what makes it a KPI. Large organizations with true business divisions can subdivide. If that is you, great. If it isn't you, don't spend your time one it.
OKRs - Experiment and scale as necessary. I mentioned using Weekdone, and I think it is a fine tool with a nice free-to-use option for getting started. You could also create some basic OKRs for teams for a quarter and use a spreadsheet to track them. That would be a fine way to start. Just be sure you're getting the spreadsheet out periodically and discussing it.
Engineering Metrics - Here you need a tool. There are a number of these now, and I do not have experience with all of them, but engaging your development team in understanding their work better is the key here - fine a tool that helps you engage them in understanding their work and how to get more done. What are the roadblocks? What works well? What is challenging? To the extent that it is possible: get the teams themselves to engage with and suggest ways to use these numbers. Homegrown metrics that are seen by the team as serving them or their fellow devs is the maxim you should go with. Make suggestions, sure. But the more this can be owned by the people building stuff, the better off you'll be. Here are few tools that are available in this space, I do not know all of them well:
Positive Behavioral Metrics - I think a tool is helpful here, but not 100% necessary. A tool helps you to spread the positive energy to more people because it can do automatic emails, texts, or messages. Those messages give you a boost, show your employees and bosses that you spread that energy, and gives all of them a boost too. Just sending an email to 1 person and tracking the info in a spreadsheet doesn't do those other things. I've had to build this tool myself at several companies and I have basic source code to do it. I am currently developing an open source solution, and when I get it done I will share. There are tools for employee recognition out there, I do not know how well any of them solve the core problem of multi-person recognition, up-chain recognition, general positive energy flow in organizations, and principle-based recognition. Those are the core tenets of what my solution does (and has always done).
In the absence of a great tool, you simply have to find ways to spread as much positive energy as possible and make sure you are up-reporting (sending your kudos to the person and that person's boss or boss's boss or both). Not the world's worst assignment. As one CEO that I worked for said to me, "One of the best parts of my job is going around recognizing people for all the great things they do." So, sending her emails about my team's successes was not hard for me to do. It made her feel good, it made my employees feel good, and it made me feel good. That's some positive energy.
If your method doesn't immediately enable superb reporting, try to keep a record somewhere - you can even use email history.
 Jonathan Fries on .
Jonathan Fries on .