The Great Resignation: A Few More Thoughts
Posted by Jonathan Fries on .
Jonathan Fries on .
As I was writing the post on Celebrating Every Departure It got me thinking about The Great Resignation and my previous thoughts on the impact of changes (organizational, family, personal, societal) on an employee. To sum it up: with every change comes an emotional journey that looks like this (up on this scale is positive, energizing emotions and down is disturbing, energy-draining emotions):
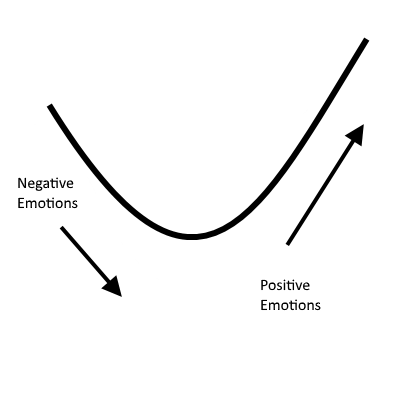
I borrowed this from Dr. Alan Watkins, especially his book, Coherence
The emotions, as one steps through this process look like this:
- Denial
- Resistance
- Anxiety
- Frustration
- Despair (bottom of the curve)
- Exploration (starting go up)
- Discovery
- Adjustment
Section 1 - The Current Situation
When you add up everything that is going on in the life of most humans (aka employees), it is a lot. COVID, worldwide economic challenges, political drama, and family add up to a lot of stress that is unavoidable. And I did not yet mention work.
Depending on where you work, where you are in your career, what you do - there is a lot happening as well. What you end up with is a lot of overlapping curves that look like what I've shown above, but all happening at once and all happening with different amplitudes and wavelengths. The experience of change and its emotional aftermath looks like this for many humans today:
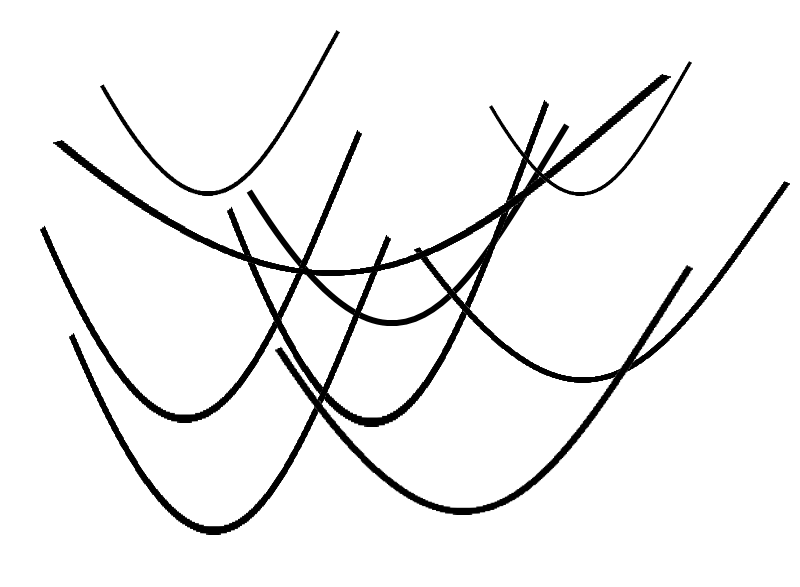
As leaders, we can either recognize this and do what we can to help our employees manage the changes and stress level that come along with this, or we can prepare for them to look elsewhere for those who will.
Managing this does not mean that we can help them with everything in their personal life or if they choose to over identify with external forces. We can't. We can help them isolate what is work related and what isn't and seek to understand where they are on those slopes, and see if we can help them.
For direct reports in many situations, it is also appropriate and helpful to know what is going on in their life and have a sense of what other events may be impacting them. This is probably obvious, but that does not mean that you can effectively help them with how they are managing the change. A helpful way to think of this is to look at the work related items and be willing to dig in on those (and to acknowledge there is often more than one). Perhaps something like this:

Section 2 - Responsibility
All of this can be very trying, for everyone. There's a lot going on in the world and to have it show up on top of work challenges is difficult. There's a temptation I feel at times to revert back to my earlier approaches. This largely consisted of ignoring people's personal problems and emotions. In my head, this sounded like this, "Focus on the work while you're at work and worry about your home life when you're at home."
This works for some people, but for a lot of others it doesn't. Some people are good at compartmentalizing, and some people are good for a while until they aren't. But even for them it doesn't mean that they aren't experiencing these things. The curves in green are still there and they are still the concern of leadership, if you want top performers and if you want your projects to go well.
So, I'll say this: none of this is your responsibility. Managing emotions is the responsibility of every individual.
But knowing and caring and guiding are things that you can do and that you may want to do, and they can be done in the name of performance and outcomes.
Regardless of the kind of leader you want to be, you employ humans (most of you) and that means that they experience this. You aren't responsible, but guiding people and offering help can lead to higher performance and better outcomes.
Section 3 - What You Can Do
Here is a list of things (some that I've been a part of implementing, and some that sound like good ideas) to deal with the large rate of change inside and outside the workplace:
- Multi-level Check-ins - having additional check-ins with individuals outside of the normal supervisor check-ins. This is informal, but I do try to meet with a wide swath of employees, regardless of level. I have heard of companies implementing official programs to encourage directors/VPs/C-Level folks to meet with people below their normal direct reports. This gives you a gauge on what is happening and a chance to let people talk outside of normal meeting conventions, relationships, etc.
- Starting Something New - a good remedy for all this change is more change. I've found that starting new programs, get-togethers, professional development opportunities, happy hours, volunteer opportunities, etc. can be good for people to have something to look forward to. This does not directly address the challenge itself, but it helps to balance the scales and see companies listening and operating in a positive way.
- Willingness to Listen - a bit of a cliché, but true none-the-less. Be willing to listen (for real and in an active way) and search for places to use insights you gather.
- Train Others to Listen, Especially New Managers - Often when people are transitioning into management they want to see things happen a certain way, or they believe that leading has to look a certain way. This type of certainty usually leads to not listening well to others. Listening and ideas can be seen as challenging to this orthodoxy or that orthodoxy because people don't agree or simply don't understand. Listening can help with that.
- Be willing to circle back around to challenging topics without waiting for others to bring them up.
- Follow Up - do the stuff that you say you are going to do.
- Discerning Transparency - Where it doesn't damage the business, share what is going on.
- Positive Reinforcement - Balance the noise and challenging emotions with your own voice - let people know how they are doing, and reinforce the things that are going well. Always link your positive reinforcement to specific, concrete things. Saying "Julio is great." or "Regina did an awesome job." is almost like saying nothing at all. Better to say, "Julio really killed it in the client presentation yesterday, he was totally prepared and was able to respond to the client's questions in real time." This is real, positive reinforcement that focuses on what you want to recognize.
- Compassion - Have compassion for those around you. It is easy to look at things through the lens of numbers or through the lens of your problems and why certain things are hard for you. Try to look at it through other people's eyes and understand where they are coming from.
Change is hard. The big the change the greater the impact on an organization and it's people. A great leader understands this and constructs an organization to help people gather their own strength and bring their best to a business.
We can't protect people from change, but we can give them support to bolster their own resilience and a place where they know they will be listened to.