Whenever I go and sign up for any particular cloud provider, or add a new service, I always have a moment of panic that sounds like this in my head:
"How much will this cost? How much is this already costing me, RIGHT NOW at this VERY MINUTE?"
Because the answer, if you aren't careful, could be a lot of money.
So, I am improving my skills with all of the cost dashboards, and I have even provisioned an AWS Organization in such a way as to track the cost of my AWS DeepRacer contest participants (not as simple as I thought it would be).
But it is difficult to understand what is turned on at any given second and what is being charged for.
It would be nice to have a Panic Report that would show you everything that was operational and let you see what the per hour or per second charge for that thing was.
Perhaps this runs counter to the notion of "don't make it hard for the customer to give you money" or "encourage them to sign up for everything and don't show the cost until the bill arrives", but I have to believe that these companies are not that shortsighted.
Side note: I am signing up for IBM Cloud and Oracle Cloud, in the interest of seeing if I can pull in the same information to pricekite from those folks that I did for the Google Cloud, Microsoft Azure, and AWS.
So far, I think the answer is 'No', but we'll see.
With Oracle, I am unable to even sign in at this juncture. Their sign in process is very much 'not like the others' and seems hyper-focused on enterprise.
I guess that makes sense for them, but it is frustrating. I guess I won't accidentally be giving them any money.
The new version of Pricekite is up, which I am labeling 'beta'. It allows for interactive comparison of serverless compute pricing across Google Cloud, Amazon Web Services, and Microsoft Azure. It is located here. And the code is also on Github.
I'm pretty happy with the current results. You can repeat the results of the earlier blog, exactly. Meaning that my math was right. Though the fact that they Azure SKUs count things in 10s instead of 1s through me for a loop momentarily.
Here is the core research tools that were used to do this, along with the cloud providers private APIs:
The Google SKU explorer is very helpful, I wish all the providers would add such a feature.
You can also complete the extended analysis I mentioned in my blog notes. In order to run those scenarios you increase the number of functions, transactions, or any other parameter and see how the effect of discounts dissipates, with larger volumes.
My original scenario was:
2 Functions
12,960,000 Executions/Month
512 MB Function Memory
200 ms/execution
In this scenario (which is substantive) AWS is the clear winner, because of their discounts. However, when you increase the functions to 32, Azure becomes the less expensive option because of their lower (by a little bit) base pricing.
For my last post comparing serverless offerings on a number of angles, I was struck again by the complexity of cloud pricing, which I alluded to at the end of the article.
Of course there is the great convenience of the cloud and all that it does for us, but there is also the substantial complexity of all that is offered, and the way it is priced.
This is a good article to read if you are thinking about this stuff:
My biggest beef is that I have to do actual research to understand the skus and how they work, in order to do price comparison. The APIs themselves do not (in any way shape or form) describe the service offering.
So: I Google, I read, and I figure it out. At least Google now offers this:
Which is a very helpful research tool, for their own cloud offering.
The other providers should do something like it. And they should give you programmatic access.
These systems all lack some definitive way to identify the pertinent skus. As a result, I'm hardcoding things (for now) and thinking about how this could be done better in the future.
Even if the values are stored in a database or configuration, I will need to add new ones, stay up to date, etc.
For real dynamic pricing, it would be better if there was an API that could be called to retrive relevant skus for any given service. Something like this, "Dear AWS, please give me all skus relevant to pricing of Lambda functions in East US 1". This would SHOULD be a simple API to use, and they have all the information to build it but they don't think about things that way.
The Google tool sort of does this, but you get back much more information and you still have to sort through skus to figure it out.
Anyway, billing APIs are not sexy nor are they money makers for these guys, but meaningful automation that will matter to the CFO will depend on services like this.
If I have to maintain a list of skus, then my pricing engine will always be a bit brittle. Fine for research, not great for prod.
As part of my Pricekite(also on GitHub) development work, I have been digging deep into the pricing model and use of serverless functions, this post will summarize statically, what you can find dynamically on Pricekite - from a compute cost perspective.
We will also look at development approaches and options for the serverless functions options from the three big players:
AWS Lambda
Google Cloud Functions
Azure Functions
Pricing
Winner: AWS
AWS and Azure
AWS and Azure price in more or less exactly the same way. They price based on what is called a Gigabyte-second. This unit of measure expresses the cost of a function using a gigabyte of memory for 1 second.
If you do not have a full gigabyte provisioned, then the amount charged for an actual clock second is a fraction of that amount. Or if you have more than a gigabyte, it is a multiple of the rate.
Both Amazon and Azure also charge for invocations. For the examples below I am assuming that the functions have allocated 512 MB of memory, which means that any function will be charged for a half GB-second for every clock second it runs.
Google
Google prices based on a memory allocation for time and for processor time, instead of rolling those into a single measure. This provides for more granularity in their pricing and probably lower pricing for workloads using less memory.
Since the CPU size you get is tied to the amount of memory, and we are using 512 MB for the memory, the CPU we are using has a clock speed of 800 MHz.
Pricing Scenarios
In order to try and make this somewhat sane we are using the following assumptions:
Function has a run time of 200 ms, regardless of platform.
Function is assigned 512 MB of memory.
On Google Cloud this implies an associated clock speed of 800 MHz.
The month we are discussing has 30 days, and therefore 2,592,000 seconds.
Each function (running 200 ms) will be invoked 12,960,000 times in the 30 day period.
We will look at the following 2 scenarios and compare prices:
A system that consists of 2 functions that run non-stop over a monthly period.
Price for 1 function running non-stop for a month, minus all discounts.
The first scenario is meant to show a reasonable amount of use that is still impacted by the discounts.
I understand that the exact scenario is unlikely, but it represents a pretty significant amount of invocations and CPU time. This same number of invocations and CPU time could be spread out over 5 or 10 or 100 functions, and the computations would be the same (assuming each function ran at 200 ms per invocation).
The second scenario is important because as you scale up the discounts will come to mean less and less, this scenario gives the sense of a per unit price, that actually represents real work.
Scenario 1: 2 Functions
Because we are running 2 functions at 512 MB memory, the GB Seconds is equal to:
AWS' discounts still matter a lot at this point. The 2 million GB Seconds add up to a lot.
Google's higher per invocation charge hurts them. It costs you more, the quicker your functions run. Said differently: if you have long running functions (200 ms is not long running) you will spend less on those pricey invocation charges.
Google is, overall, more expensive. They charge for more types of things and they charge more for those things.
Scenario 2: 1 Function, No Discounts
This is not a real world scenario (since discounts would apply), but the more functions you run, the smaller % of the total the discount is going to be.
So, if we consider a single function at 512 MB running for a full month (2,592,000 seconds) as our unit. What is our per unit cost, as we scale up?
AWS
AWS Item
Rate Per Unit
Unit
Units Consumed
Units Charged
Cost
CPU/Memory
$0.0000166667
GB Seconds
1,296,000
1,296,000
$21.60
Invocations
$0.0000002
Invocation
12,960,000
12,960,000
$2.59
Total
--
--
--
--
$24.19
Azure
Azure Item
Rate Per Unit
Unit
Units Consumed
Units Charged
Cost
CPU/Memory
$0.000016
GB Seconds
1,296,000
1,296,000
$20.74
Invocations
$0.0000002
Invocation
12,960,000
12,960,000
$2.59
Total
--
--
--
--
$23.33
Google Cloud
GCP Item
Rate Per Unit
Unit
Units Consumed
Units Charged
Cost
CPU
$0.00001
GHz Seconds
2,073,600
2,073,600
$20.74
Memory
$0.0000025
GB Seconds
1,296,000
1,296,000
$3.24
Invocations
$0.0000004
Invocations
12,960,000
12.960,000
$5.18
Total
--
--
--
--
$29.16
Take aways from Scenario 2:
Azure's per unit price is lower, but not by much. Once you have 32 such functions (of traffic equivalent to that) and your bill is over $730, Azure's lower per unit makes up for Amazon's initial discounts. So, if you have that kind of traffic, Azure is more cost effective.
Google's per unit price is higher. Long-running functions would cost less, but probably not by enough to make a difference. They're still the more expensive option.
It is also interesting to note that Azure's published rate on their website of .000016, is less than what comes back from their pricing API for any region. So, if you look at pricekite.io, the numbers are different.
I am assuming for the purposes of this analysis that their published numbers are correct.
Local Development
Winner: Microsoft
But of course, compute cost alone is not everything. For many implementations, labor costs and support costs will also factor in as a significant cost of the solution. So, next we will look at the tools that go in to working on these serverless functions.
By local development, I mean what does it take to work on these serverless functions, if you are going to work on your local machine? This is in contrast to working in the web-based editor that each company provides. I will cover the web-based editors below.
Microsoft
Developing locally with Microsoft means using Visual Studio. There may be other ways to do it, but if you are already a .Net developer then you have Visual Studio. If you do, then creating functions, running, and debugging them is very simple and easy to do. It even lets you emulate azure storage locally OR connect to your azure subscription and use real Azure resources. This is amazingly simple and comes with all that you need to do local development.
It is even easy to set breakpoints in the code (just as you'd expect from any other C# development in Visual Studio). There are code templates (in VS 2019) you just select, walk through the wizard, and you are up and coding.
Also, Microsoft is clearly the cloud of choice if you are already a .Net shop and like writing C# code.
A few screen shots:
Code Templates and Built-in Azure Integration make Visual Studio easy to work with.
Google
Google does not have a tool anything like Visual Studio. So if you are going to work on Google Cloud Function code locally, you will be using your favorite editor: Web Storm, Atom, etc.
The nice thing about working locally is that Google Makes this very easy through some local tools that you can install on your computer via NPM, and which can be started off with a couple simple command lines using their Functions Framework.
All in all it is very easy and works out of the box if you are used to node.js and NPM, which you should be if you are going to write Google Cloud Functions.
AWS
The truth is, I did not get it to work.
In order to do local development you need several things installed which I did not have AWS-CLI and Docker, being the two I can remember off the top of my head. I did get them both installed (eventually) and running.
I was able to run the template creation of a basic "Hello World" but when I ran it, it failed. I believe the problem was with Docker. The only online help I found with my problem was to ensure that I was running Linux and not Windows Docker containers, but I was already doing that.
I believe that it does work. And if you are more deeply enmeshed in the AWS world, you can probably get this working, without any problem. I didn't. Compared to the other two it was hard.
For the record, I had to install VS 2019 on a machine which had never had any previous version of VS on it. It took a while, as VS installs do, but everything worked exactly right, out of the box, the first time.
I spent probably 1 - 2 hours messing with local Amazon development before I gave up.
Cloud-Based Development
Winner: Amazon Lambda
Now we will talk about doing development in the web interface. This is where Amazon really shines. They bought a company called Cloud9 (web-based IDE) a few years ago and it shows.
You can still use Cloud9 as a separate, web-based development product for other development, some features and UI concepts have been brought in to the Lambda funciton editor.
Amazon
There is a lot to like about doing Lambda function development inside of the AWS Console. My maybe-favorite thing, is not really a development thing at all. It is this:
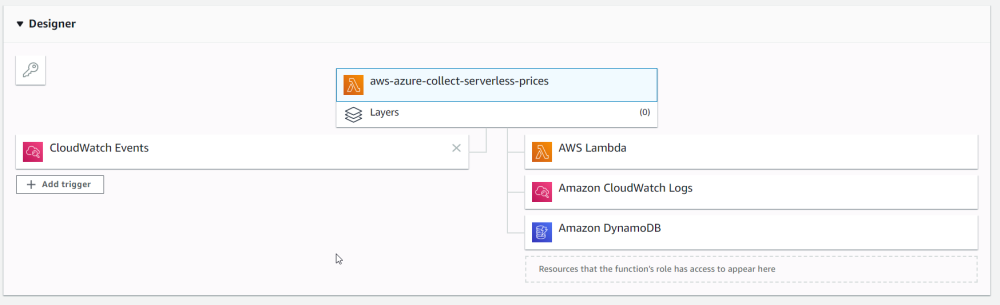
The Designer
This Designer thingy shows you all of the Lambda function's permissions in a neat user interface. I don't know if Amazon thought of this or it came from Cloud9, but it is genius and very helpful and every system in the world should copy it. Azure especially needs this.
The development piece is straightforward, has good syntax highlighting and catches pretty much all your syntax errors for you.
There is built in testing, log tracing, performance configuration, permissions, performance monitoring, and network info. And it is all on one page, intuitively laid out, helpful, and easy to use. This is where AWS maturity comes into full view.
There are times in life where you have to sit back and appreciate what I call a million dollar page or screen This right here is a million dollar web page, and it is a million dollars well invested.
The main drawback is that you cannot simply add node.js packages to the web-based editor, you can only do that locally. But I honestly found that the included packages work for all my use cases. The built-in packages include the AWS JavaScript SDK (I evaluated node.js, not python), which has A LOT of functionality.
Microsoft
Microsoft probably gets second place, as there are some things that they do really well. You can easily add additional dlls for references to have your code do more. The code editor (for C#) is on par with AWS in terms of syntax checking and highlighting. And the built in log-tracing was even better (when it worked).
Only sometimes it didn't work. Sometimes it just stopped working for reasons that I never completely understood, causing me to have to reload the page (annoying).
Google
Google has the least exciting looking interface. And it is not nearly as full featured as either MS or AWS. There is no onscreen logging, and the process of changing code required a redeploy (10 - 15 seconds) to test it. You also have to pop in and out of editing mode, which takes time also. The best thing about Google is that they make it very comfortable for node.js developers to work there. You can edit the file with the js code (usually index.js) and you can edit the package.json file to add includes, all very easy if you are familiar with that ecosystem.
Google makes it very easy to deploy from their Cloud Source Repositories, which includes an easy integration to Git. So it is easy to deploy from an external source repository. It is all built into the UI and very clean. Honestly, I don't know if security people would love that, but it is a handy feature.
Who Should You Pick?
Well, the answer is, "It depends."
AWS has the edge in both price and online code editing, which I think makes them the strongest player.
If you are a .Net shop or have other reasons to work locally, Visual Studio's local development capabilities are very strong.
There are a lot of other real world scenarios to consider and you should consider these things as well when you are evaluating these tools:
What else does your application do?
What type of other services do you need?
What deployment model do you want?
What are your QA Automation goals?
Are you a start up?
What size of payload are you sending in to your functions?
All of those things are important, as is this question: "What are you already using?" If you have significant investment, you have to look at the cost of change, as well.
I think that you can look at this and be upset about just how complex some of these things are. But honestly, I think that from a capability stand point it is just amazing what the cloud has to offer and how powerful this stuff is. Also, if you think there isn't job security in understanding and making sense of these tools for your organization, I think you're missing the big picture.
Those are rockets and they hold up the cloud. Those black hash-mark areas are patches in the cloud where things didn't work right. Because of these flaws someone needed to sew the cloud together. The patches are comprised of 81% code and 22% duct tape.
Why don't the cables burn up in the rocket exhaust? That is because of trained monkeys wearing asbestos suits. When the cable breaks or one monkey burns up, a monkey is added to the chain.
This concludes our brief tutorial on the cloud.
Here's the deal. This was inspired by a discussion with a client about a large cloud service provider. The service provider informed the client that the hardware that their instances ran on was bad and needed to be replaced. This is not the first time this has happened.
To me this revelation of 'hardware problem' feels tone deaf because everything about the cloud (which I mostly love) is predicated on us (the customers) not caring about hardware anymore: pricing structures, product offerings, marketing materials, billing. It seems wrong to then blame the hardware when it is convenient. My client didn't ask for you to tie their instance to some faulty hardware. My client had previously been entirely oblivious (and rightly so) to what hardware the instance ran on. Why don't they just quietly move the VM and fix the problem themselves?
Even if it was totally manual, it would give me a lot more faith in the magic and that they have their stuff together.
Truly, I love the cloud. Even if it is imperfect, it powers a lot of the modern world (including this site). I love it mostly because it is a technical marvel and it empowers business, but this customer service flaw makes me doubt the technical greatness. Why do that?
I really believe that cloud, IoT, and mobile technology are job creators in the long run, because there will just be so much of it.
Just, please, don't blame the hardware when the rest of the time you don't want me to think about it.
 Jonathan Fries on .
Jonathan Fries on .