Firebase Software Development Positive Behavioral Metrics
Firebase Errors for Humans - aka Best Error Ever
Posted by Jonathan Fries on .
Jonathan Fries on .
I'm working on a system for positive behavioral recognition and metrics using Firebase and React. This is a hobby/side project that I work on usually on nights and weekends.
This weekend I had an issue with Firestore (the newer of the two data solutions inside the Firebase product). I was querying on multiple data attributes in a collection. This is not allowed in Firestore, unless you have created an index that includes those two attributes.
I had no such index, so I got this error:

Yes, the short answer is that that link says, "You can create it here." And you can click on it and it takes you to the page where you can build the index.
AND...
And it has pre-populated the index for you with the two fields that you need so that you can click, "OK". And the index builds, just like you need it:
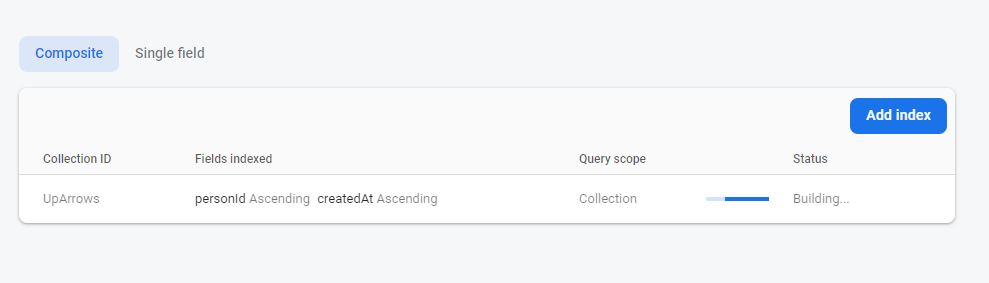
This is really pretty amazing and I have never seen an error like this.
Often, errors are very generic and it takes time to search through forums trying to find someone with the same error who is actually having the same problem as you.
I have seen a number of errors in React that offer suggestions as to where your bug is and they are often correct. This is very helpful and a huge improvement.
The Firestore error takes that level of customer service to a new level: here's your problem, here's how to fix it, and here's a link that will basically fix it for you.
I would very much like to see more of this.
What has happened here is that someone at Google (Firebase is a Google product) has applied the ideas of user experience to the error handling in their product. Developers are the users of the error system, so thank you for that!
Firebase is a web-based product, so there is no reason why it can't know enough to point you in the right direction.
If you are in software development, though, you can appreciate that this is a high bar to jump over:
- Someone had to think of this early on, so that it could be woven into the product.
- Leadership had to include time and budget to implement it.
- Their UX had to be consistent enough to allow it.
- The error system handling system had to be built smart enough to make it all work.
All of this to say - a lot had to happen technically, organizationally, and culturally to make this happen.
When you think about the amount of time that often goes into error handling and management, it makes this all the more amazing.
Developers ARE the users of your error system, your API, your toolkits, and your documentation. Doing things like this makes your tool attractive to developers, managers, and business decision makers.
Why managers and business decision makers? Because it makes good developers better and faster, and it makes new developers far more productive than they would be if you didn't have it.
New developers spend a lot of time searching for answers online and asking more senior team members for help. Imagine a world where the platform itself can answer your questions and guide you through solving the problem.
Kudos to Firebase/Google on an amazing innovation.
