Cloud Multi-Cloud Pricing
Cloud Pricing - A DevOps Feature Suggestion
Posted by Jonathan Fries on .
Jonathan Fries on .
I wrote about this in an earlier post.
Google will begin charging for in-use, public IP Addresses on January 1, 2020. Is this the much ballyhooed supply crunch for IP v4 addresses in it's early stages? Probably not.
My guess is that it is simply a reflection of the fact that Google sees this as a chance to recognize some revenue from a product/service that it has been giving away previously. And no one is going to switch cloud providers because of a few bucks they get charged for an in-use IP Address.
So, why write a blog about it?
Because it is December 18th and they still haven't published a SKU for it, which makes it hard for me to update my IP Address pricing tool on pricekite.io. This is mildly frustrating since I have some personal time this week in advance of the holidays and I was hoping to make this change.
For now, my information on pricekite remains accurate, in that I published the prices when Google published them. However, I would like the dynamic piece of this to work correctly. Right now it is simply hard-coded in the UI - not the most elegant solution.
In any case, this speaks to the generally opaque way that pricing and product SKUs work in the cloud world. SKUs are published, but the exact way in which they work, interact, and are used to charge your bill is sometimes hard to understand. Which SKUs apply? How are the discounts accounted for? Is it one SKU or many? how exactly will I be charged for what I am creating.
Each cloud provider has its own approach to this and actually Google has a decent tool here. But it still isn't perfect or always clear how it will work.
It would be great if the cloud providers would create a cloud pricing tool (similar to the way the Lambda permissions tool works) that showed you exactly which SKUs you were using, how discounts are likely to apply, and forecated cost with the ability to tweak scenarios.
Here is how the Lambda resource visualization works:
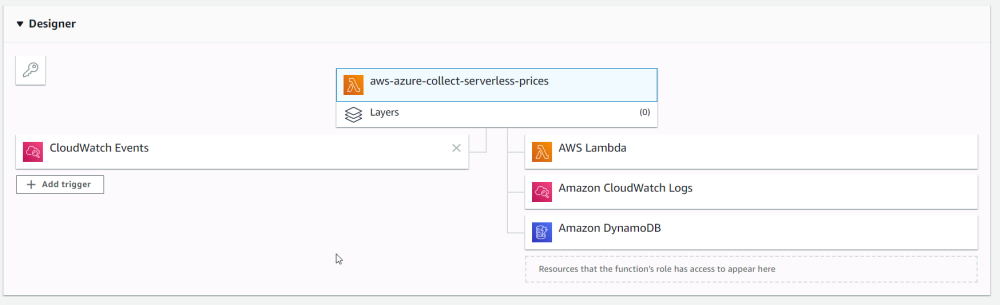
To go a step futher, I'd like to see suggestions (based on DB structure or code being written) for how to reduce cost or make smarter choices. I believe this would be achievable, although might be difficult to do.
This visualization would show all the SKUs that would be used based on the current configuration and code of a particular service, and it would have some inputs to allow you to tweak scenarios and understand the cost of your choices.
This would allow developers to truly embody the DevOps mindset we all are striving for. How does my code choice impact the cost of this solution? As currently constructed, no cloud provider offers this type of functionality.